Broctld
Overview
From the user’s perspective, broctld is a single, persistent system service. The service gets started/stopped through the OS’ standard mechanism for managing system services (e.g., init.d scripts, systemd, launchctl). When the service is running, it manages all the Zeek processes running on the system; and it offers an API to the broctl client application that allows the user to control the setup. That new client application offers the user functionality very similar to the current monolithic broctl script.
In cluster settings, we run one of these broctld services per system. The broctld on the master node controls all the other nodes through connections to their broctld instances. broctl connects only to the master’s broctld, which passes commands on to the other nodes as necessary. For more distributed settings, we extend this scheme to a tree of broctld services forming a hierarchical set of nodes monitoring different parts of a network. Commands gets pushed down the tree from the master broctld, which’s children pass them on to their successors. Likewise, any feedback from child nodes (e.g., status information) gets propagated back up the tree.
We no longer push any of broctld‘s code from the master node to other nodes. Each node must set up broctld on its own, e.g., through the standard OS packaging system. Likewise, each node must ensure the broctld service is running configured appropriately to find and connect to its upstream broctld.
Broctld Architecture
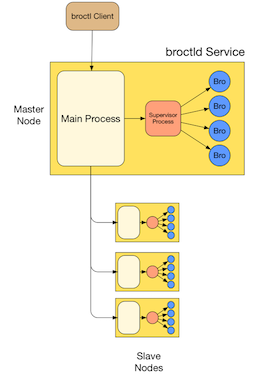
Objectives
- broctld is a persistently running system service that spawns Zeek processes as needed.
- broctld constantly supervises the Zeek processes that it has spawned. If one of them dies, it immediately restarts it.
- Restarting broctld should generally not affect the Zeek processes; they need to keep running, and return to being under control of the new broctld instance. This allows for configuration changes, upgrading, error recovery, etc., without causing monitoring outages.
Design
We divide the broctld service into two parts that run in two separate processes. Most of the logic resides inside the "Main Process"; that one implements configuration, API, logging, inter-node communication., and almost everything else. The one thing that the Main Process doesn’t do is the supervision of the Zeek processes: that’s performed by a separate "Supervisor Process", which the Main Process controls.
When the broctld service starts up, the Main Process receives control first. Initially, no Supervisor Process will be running yet. The Main Process then spawns up a Supervisor Process and sets up communication between the two. A freshly started Supervisor Process will initially not yet be controlling any Zeek processes. To start them, the Main Process instructs the Supervisor Process to spawn them; the supervisor Process then keeps the Zeek processes running until the Main Process explicitly signals to stop some, or all.
The Main Process can shutdown its operation without stopping the Supervisor Process process, allowing for example to upgrade configuration or code without impacting the Zeek processes. Once the Main Process starts up again, it will notice that a Supervisor Process is already running and will connect to it through the communication channel already established by the previous instance.
When the broctld system service gets shuts down through the OS, that means both broctld and the Zeek processes need to terminate. The Main Process first instructs the Supervisor Process to stop the Zeek processes. It then terminate the Supervisor Process, and finally shuts itself down.
Implementation
The advantage of the separate Supervisor Process is that usually Zeek processes will be able to keep running unaffected even if the Main Process terminates, or otherwise gets into trouble. To fully exploit that potential, we need to keep the Supervisor Process as minimal and robust as possible, and ideally reuse an existing, stable supervisor implementation. A good candidate seems to be leveraging supervisord, as it’s established & robust, and written in Python. While we won’t need a lot of its features, reusing the existing project would avoid the effort of creating a robust supervisor from scratch. We need to investigate if reusing supervisord is a viable route.
APIs
We will have two APIs: one between the broctl client and the broctld service; and one between broctld services running on different nodes.
Client API
For the client-side API, there are two options:
Use Broker to exchange control events:
- Advantage: As we’ll need Broker anyways, this will give us much of the API for free. It also generally fits well with our overall "Brokerization" strategy.
- Disadvantage: Non-standard, and cannot benefit from existing HTTP-based clients.
Create a REST-style HTTP-based API.
- Advantage: It’s easy to build further clients beyond broctl with standard tools, including just pointing a browser to broctld.
- Disadvantage: Need to build a completely new API from scratch that won’t fit nicely into our Broker-based ecosystem.
Inter-node API
For broctld-to-broctld connectivity, in principle we have the same two options as for the client-side API. However, using Broker seems quite natural here, as there’s no concern about other clients.
Schedule
Getting all the pieces together is a complex task. Here’s a proposed break-down into smaller parts.
Build out single-node deployment
- Break up the current broctl into a client/server application. The API will probably largely mimic the current set of broctl commands.
- Remove all the logic that copies Python code around. Assume broctl/broctld is installed system-wide through standard OS installation mechanisms.
- Factor out the code that controls Zeek processes so that there’s a clear API for their management in terms of simple primitives (start/stop/etc.)
- Introduce the Supervisor Process. Remove the process management code from broctld and replace it with communication to the Supervisor Process.
Build out the cluster deployment
- Set up inter-node communication between broctld services on different systems
- Design the API for the master to control slave node, including pushing out configuration and receiving status information.