Bro Cluster Architecture
Bro is not multithreaded, so once the limitations of a single processor core are reached the only option currently is to spread the workload across many cores, or even many physical computers. The cluster deployment scenario for Bro is the current solution to build these larger systems. The tools and scripts that accompany Bro provide the structure to easily manage many Bro processes examining packets and doing correlation activities but acting as a singular, cohesive entity. This document describes the Bro cluster architecture. For information on how to configure a Bro cluster, see the documentation for BroControl.
Architecture
The figure below illustrates the main components of a Bro cluster.
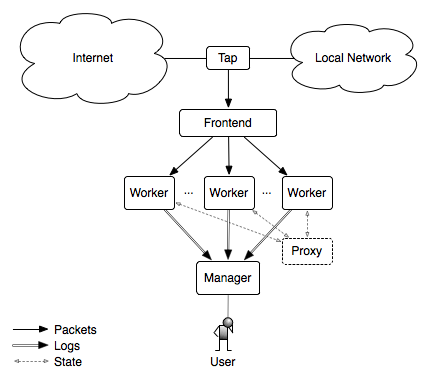
Tap
The tap is a mechanism that splits the packet stream in order to make a copy available for inspection. Examples include the monitoring port on a switch and an optical splitter on fiber networks.
Frontend
The frontend is a discrete hardware device or on-host technique that splits traffic into many streams or flows. The Bro binary does not do this job. There are numerous ways to accomplish this task, some of which are described below in Frontend Options.
Manager
The manager is a Bro process that has two primary jobs. It receives log messages and notices from the rest of the nodes in the cluster using the Bro communications protocol (note that if you are using a logger, then the logger receives all logs instead of the manager). The result is a single log instead of many discrete logs that you have to combine in some manner with post-processing. The manager also takes the opportunity to de-duplicate notices, and it has the ability to do so since it’s acting as the choke point for notices and how notices might be processed into actions (e.g., emailing, paging, or blocking).
The manager process is started first by BroControl and it only opens its designated port and waits for connections, it doesn’t initiate any connections to the rest of the cluster. Once the workers are started and connect to the manager, logs and notices will start arriving to the manager process from the workers.
Logger
The logger is an optional Bro process that receives log messages from the rest of the nodes in the cluster using the Bro communications protocol. The purpose of having a logger receive logs instead of the manager is to reduce the load on the manager. If no logger is needed, then the manager will receive logs instead.
The logger process is started first by BroControl and it only opens its designated port and waits for connections, it doesn’t initiate any connections to the rest of the cluster. Once the rest of the cluster is started and connect to the logger, logs will start arriving to the logger process.
Proxy
The proxy is a Bro process that manages synchronized state. Variables can be synchronized across connected Bro processes automatically. Proxies help the workers by alleviating the need for all of the workers to connect directly to each other.
Examples of synchronized state from the scripts that ship with Bro include the full list of “known” hosts and services (which are hosts or services identified as performing full TCP handshakes) or an analyzed protocol has been found on the connection. If worker A detects host 1.2.3.4 as an active host, it would be beneficial for worker B to know that as well. So worker A shares that information as an insertion to a set which travels to the cluster’s proxy and the proxy sends that same set insertion to worker B. The result is that worker A and worker B have shared knowledge about host and services that are active on the network being monitored.
The proxy model extends to having multiple proxies when necessary for performance reasons. It only adds one additional step for the Bro processes. Each proxy connects to another proxy in a ring and the workers are shared between them as evenly as possible. When a proxy receives some new bit of state it will share that with its proxy, which is then shared around the ring of proxies, and down to all of the workers. From a practical standpoint, there are no rules of thumb established for the number of proxies necessary for the number of workers they are serving. It is best to start with a single proxy and add more if communication performance problems are found.
Bro processes acting as proxies don’t tend to be extremely hard on CPU or memory and users frequently run proxy processes on the same physical host as the manager.
Worker
The worker is the Bro process that sniffs network traffic and does protocol analysis on the reassembled traffic streams. Most of the work of an active cluster takes place on the workers and as such, the workers typically represent the bulk of the Bro processes that are running in a cluster. The fastest memory and CPU core speed you can afford is recommended since all of the protocol parsing and most analysis will take place here. There are no particular requirements for the disks in workers since almost all logging is done remotely to the manager, and normally very little is written to disk.
The rule of thumb we have followed recently is to allocate approximately 1 core for every 250Mbps of traffic that is being analyzed. However, this estimate could be extremely traffic mix-specific. It has generally worked for mixed traffic with many users and servers. For example, if your traffic peaks around 2Gbps (combined) and you want to handle traffic at peak load, you may want to have 8 cores available (2048 / 250 == 8.2). If the 250Mbps estimate works for your traffic, this could be handled by 2 physical hosts dedicated to being workers with each one containing a quad-core processor.
Once a flow-based load balancer is put into place this model is extremely easy to scale. It is recommended that you estimate the amount of hardware you will need to fully analyze your traffic. If more is needed it’s relatively easy to increase the size of the cluster in most cases.
Frontend Options
There are many options for setting up a frontend flow distributor. In many cases it is beneficial to do multiple stages of flow distribution on the network and on the host.
Discrete hardware flow balancers
cPacket
If you are monitoring one or more 10G physical interfaces, the recommended solution is to use either a cFlow or cVu device from cPacket because they are used successfully at a number of sites. These devices will perform layer-2 load balancing by rewriting the destination Ethernet MAC address to cause each packet associated with a particular flow to have the same destination MAC. The packets can then be passed directly to a monitoring host where each worker has a BPF filter to limit its visibility to only that stream of flows, or onward to a commodity switch to split the traffic out to multiple 1G interfaces for the workers. This greatly reduces costs since workers can use relatively inexpensive 1G interfaces.
OpenFlow Switches
We are currently exploring the use of OpenFlow based switches to do flow-based load balancing directly on the switch, which greatly reduces frontend costs for many users. This document will be updated when we have more information.
On host flow balancing
PF_RING
The PF_RING software for Linux has a “clustering” feature which will do flow-based load balancing across a number of processes that are sniffing the same interface. This allows you to easily take advantage of multiple cores in a single physical host because Bro’s main event loop is single threaded and can’t natively utilize all of the cores. If you want to use PF_RING, see the documentation on how to configure Bro with PF_RING.
Netmap
FreeBSD has an in-progress project named Netmap which will enable flow-based load balancing as well. When it becomes viable for real world use, this document will be updated.
Click! Software Router
Click! can be used for flow based load balancing with a simple configuration. This solution is not recommended on Linux due to Bro’s PF_RING support and only as a last resort on other operating systems since it causes a lot of overhead due to context switching back and forth between kernel and userland several times per packet.